运行环境配置
在成功安装并登录 DeskFlux 后,为确保软件各项功能正常运行,您需要对本地运行环境进行基础配置。本文档将指导您完成环境检查与配置流程。
1. 环境检查清单
在开始配置前,请先点击顶部的“三个点”图标 弹出菜单选择“运行环境配置”,弹出以下配置页面
2. 关键依赖项检查
DeskFlux 的正常运行依赖于以下系统组件。请按顺序进行检查: 我们特别关注的是系统组件这栏,来确保安装的环境软件是否已经正常运行 其中的几个依赖组件的状态表示如下:
- [ ] 🟡 黄色 : 已经安装就绪,状态正常,未启动,有需求的时候自动启动
- [ ] 🔵 蓝色 : 已经安装就绪,状态正常,已启动,有需求的时候随时调用
- [ ] 🔘 灰色 : 未安装完成,不正常,未启动,需要点击右上角的“工具”按钮进行修复
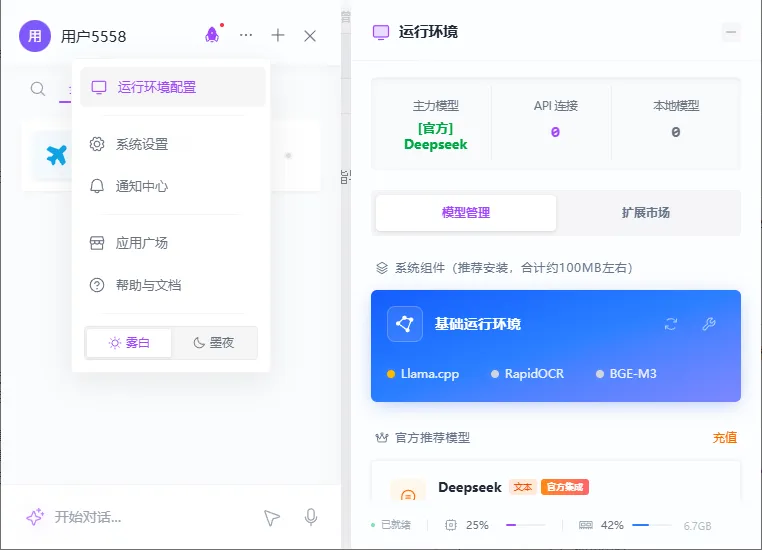
3. 环境组件说明
1. llama.app —— 大语言模型运行框架
定位:在本地运行LLaMA系列及其他GGUF格式大模型的桌面应用/框架。
核心功能:
- 无需联网,完全本地运行大模型
- 支持多种量化模型(如DeepSeek、Qwen等)
- 提供API服务接口,可供其他应用调用
本地用途:
- 运行对话式AI助手
- 为知识库问答系统提供推理能力
- 代码辅助与文档处理
2. RapidOCR —— 离线文字识别引擎
定位:跨平台、高性能的离线OCR(光学字符识别)工具。
核心功能:
- 完全离线运行,不上传图像至服务器
- 模型体积小(核心<5MB),支持CPU/GPU运行
- 支持50+种语言,包含中英文混合识别
本地用途:
- 扫描PDF/图片中的文字提取
- 合同、发票等文档自动化录入
- 截图OCR识别
3. BGE-M3 —— 多语言向量嵌入模型
定位:由智源研究院发布的通用多语言向量模型,用于文本语义理解与检索。
核心功能:
- 将文本转换为向量(Embedding),支持100+种语言
- 支持三种粒度:文本块、句子、词级别
- 通过Ollama可简化部署
本地用途:
- RAG知识库的文档向量化
- 语义搜索与相似度匹配
- 智能体(Agent)的上下文检索
组件关系与典型工作流
graph LR
A[文档/图像] --> B[RapidOCR]
B --> C[提取文字]
C --> D[BGE-M3]
D --> E[向量化存入知识库]
F[用户问题] --> G[BGE-M3]
G --> H[检索相关片段]
H --> I[llama.app]
I --> J[AI回答]